



最高の仮想通貨情報をあなたの受信トレイに直接お届けします。.

- Anthropic は、任天堂のゲームボーイのポケモン レッドを使用して、最新の Claude 3.7 Sonnet モデルのベンチマークを実施しました。.
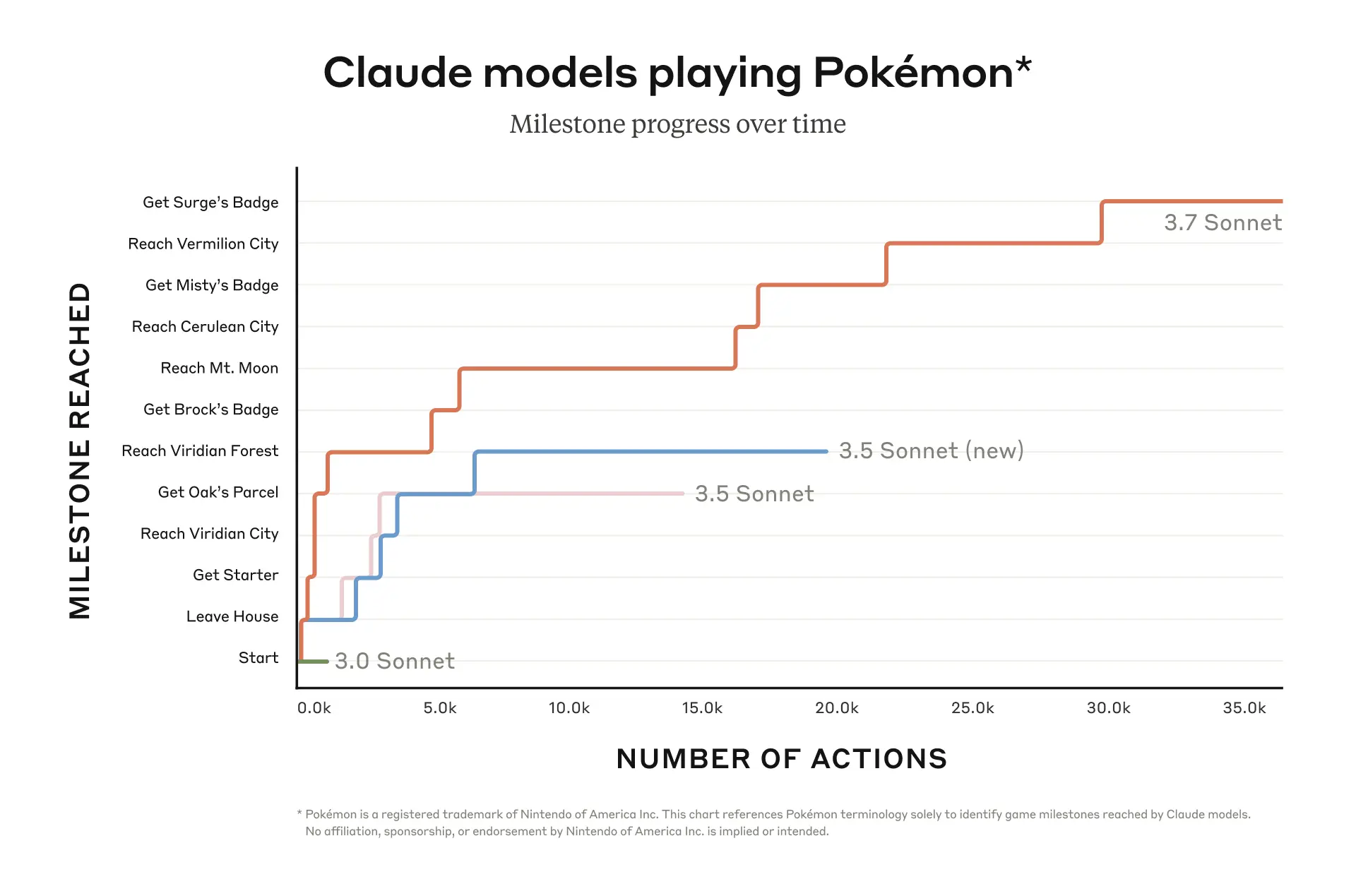
- このモデルはゲーム内で 12 のマイルストーンを達成し、35,000 以上のアクションを実行できました。.
- クロード 3.7 Sonnet は、問題の複雑さに応じて、ユーザーが望む限り「考える」ことができます。.
アンスロピックは、最新のAIモデル「Claude 3.7 Sonnet」を classic ゲームボーイの名作ゲーム「ポケットモンスター 赤」でベンチマークしました。このモデルは以前のバージョンと比較して大幅に性能が向上し、ゲーム内で12のマイルストーンを達成しました。.
最近の ブログ記事、最近実施したテストの詳細を明らかにしました。同社は、Y軸にゲーム内の「マイルストーン」、X軸に「アクション数」を示すグラフを公開しました。3.7 Sonnetのパフォーマンスを、3.5 Sonnet(新モデル)、3.5 Sonnet、および3.0 Sonnetと比較しました。これらのモデルの中で、3.7は明らかに優れたパフォーマンスを発揮し、合計12のマイルストーンを達成するために35,000以上のアクションを実行しました。ゲーム内で3人のジムリーダーに勝利し、それぞれのバッジを獲得しました。比較のために、Anthropicの以前のモデルである3.0 Sonnetは、数千のアクションしか実行できず、ゲームの初期ステージを通過することができませんでした。
最近のゲームプレイテストに関して、アントロピックは「ポケモンはClaude 3.7 Sonnetの能力を評価する楽しい方法ですが、これらの能力はゲームをプレイするだけでなく、現実世界にも影響を与えると期待しています」と述べています。
Claude 3.7 Sonnetのユニークな特徴の一つは、「拡張思考」を採用していることです。DeepSeekのR1やOpenAIのo3-miniと同様に、Claude 3.7 Sonnetはより困難な問題を推論することが可能です。これは、より多くの時間と引き換えに、より多くの計算能力を使用することで実現されます。.
クロード3.7が上記のマイルストーンを達成するためにどれだけの計算能力を消費したかはまだ明らかではありません。また、Anthropicは、モデルがゲーム内の最後のジムリーダーであるサージに到達するのにどれだけの時間がかかったかを明らかにしていません。.
『ポケットモンスター 赤』でのテストは、新しいモデルの能力を軽く示すためのものに過ぎないと考えるのが妥当でしょう。これは、新しいモデルが高度な推論能力を持ち、より複雑な問題を解決するために(必要であれば)より多くの時間を要する可能性があることを示しているにすぎません。実際、研究者たちはこれまでも、 ストリートファイターやチェスなどのビデオゲームをプレイさせることで、モデルの能力をテストすることから始めてきました。
クロード3.7 ソネットはユーザーが望む限り考えることができる
どうやら、Claude 3.7 Sonnetはユーザーが望む限り思考を続けることができるようです。リアルタイムの回答と綿密に考え抜かれた返答を提供することから、「ハイブリッドAI推論モデル」と謳われています。推論機能をオンにするかどうかはユーザー次第であり、Claude 3.7 Sonnetが問題に費やす時間はユーザーによって増減します。.
ここでの目標は、オプションを簡素化することでユーザーエクスペリエンスを向上させることにあるようです。今日のチャットボットの多くには、平均的なユーザーにとってやや分かりにくいモデルピッカーが搭載されています。これらのモデルは通常、さまざまな設定があり、機能も異なります。例えば、OpenAIのChatGPTも幅広い機能を提供しています。.
実際、サム・アルトマン氏は最近、OpenAIの 最新ロードマップ 、ChatGPTのサービスを統合し、ユーザーが外出先でも問題解決のためのソリューションを検索できるようにすることがOpenAIの長期目標だと述べています。その意味で、ChatGPTもエージェント中心のアプローチを採用する可能性があると言えるでしょう。
Claude 3.7 SonnetはDeepSeek R1やo3-miniよりも高価です
Anthropicは月曜日に開発者とユーザー向けにClaude 3.7 Sonnetをリリースしました。ただし、このモデルの推論機能はプレミアムチャットボットプランを選択したユーザーのみが利用できます。現時点では、入力トークン100万個あたり3ドル、出力トークン100万個あたり15ドルです。つまり、ユーザーは3ドルで75万語を入力できることになります。そのため、DeepSeekのR1やChatGPTのo3-miniよりも高価です。ただし、これら2つのモデルはClaude 3.7 Sonnetのようなハイブリッドではなく、厳密に「推論モデル」です。
推論モデルは一般的に動作が遅く、質問に答えるのに時間がかかります。例としては、xAiのGrok 3(Think)、GoogleのGemini 2.0 Flash Thinking、DeepSeekのR1、そしてもちろんChatGPTのo3-miniモデルなどが挙げられます。.
Anthropicの製品・研究責任者であるダイアン・ペン氏によると、同社はユーザーが明示的に設定を選択するのではなく、Claudeが問題について考える時間を自分で決められるようにしたいと考えている。この点に関して、Anthropicは ブログ記事「人間が、すぐに答えられる質問とじっくり考える必要がある質問のために、別々の脳を持っているわけではないのと同様です」と述べている。
しかし、xAIのGrok 3はより制限が少なく、議論にオープンであるように努めているのに対し、Claude 3.7 Sonnetは特定の質問への回答を拒否します。実際、今月初めにはGrok 3のベータ版でトランプ氏にad*athペナルティを提案するところまで進みました。これは「ひどくひどい失敗」とされ、その後修正されたことをxAIのエンジニアリング責任者であるIgor Babuschkin氏が確認しています。.

しかし、以前のモデルと比較すると、拒否頻度は低下し、無害なプロンプトと有害なプロンプトを区別できるようになりました。Anthropic社によると、以前のモデルであるClaude 3.5 Sonnetと比較して、不要な拒否は45%減少しました。.
この記事を読んでいるあなたは、既に一歩先を行っています。 ニュースレターを購読して、その優位性を維持しましょう。
免責事項。 提供される情報は取引アドバイスではありません。Cryptopolitan.com Cryptopolitan、 このページで提供される情報に基づいて行われた投資について一切の責任を負いません。tronお勧めしますdent 調査や資格のある専門家への相談を

シュムマス・フマーユーン
Shummas 氏は、元テクニカル コンテンツ ライター兼研究者です。










速習コース
- どの仮想通貨でお金が稼げるか
- ウォレットを使ってセキュリティを強化する方法(そして実際に使う価値のあるウォレットはどれか)
- プロが使う、あまり知られていない投資戦略
- 仮想通貨への投資を始める方法(どの取引所を使うべきか、購入すべき最適な仮想通貨など)