



Les meilleures analyses crypto directement dans votre boîte mail.
Anthropic a testé les performances de son dernier modèle d'IA Claude 3.7 Sonnet à l'aide de Pokémon Rouge

- Anthropic a testé son tout nouveau modèle Claude 3.7 Sonnet en utilisant Pokémon Rouge sur Game Boy de Nintendo.
- Le modèle a pu franchir 12 étapes clés en jeu et a effectué plus de 35 000 actions.
- Claude 3.7 Sonnet peut « réfléchir » aussi longtemps que l’utilisateur le souhaite, en fonction de la complexité du problème.
Anthropic a testé son dernier modèle d'IA, Claude 3.7 Sonnet, sur le jeu classic Pokémon Rouge sur Game Boy de Nintendo. Le modèle a obtenu des résultats nettement supérieurs aux versions précédentes et a réussi à accomplir 12 objectifs dans le jeu.
Dans un récent article de blog, Anthropic a dévoilé les détails de ses tests. L'entreprise a publié un graphique présentant les « Étapes clés » du jeu en ordonnée et le « Nombre d'actions » en abscisse. Elle a comparé les performances de la version 3.7 de Sonnet avec celles des versions 3.5 (nouvelle), 3.5 et 3.0. Parmi ces modèles, la version 3.7 s'est nettement distinguée, réalisant plus de 35 000 actions pour atteindre un total de 12 étapes clés. Elle a vaincu trois champions d'arène et remporté les badges correspondants. À titre de comparaison, le modèle précédent d'Anthropic, la version 3.0 de Sonnet, n'a pu effectuer que quelques milliers d'actions et n'a pas pu dépasser les premiers niveaux du jeu.
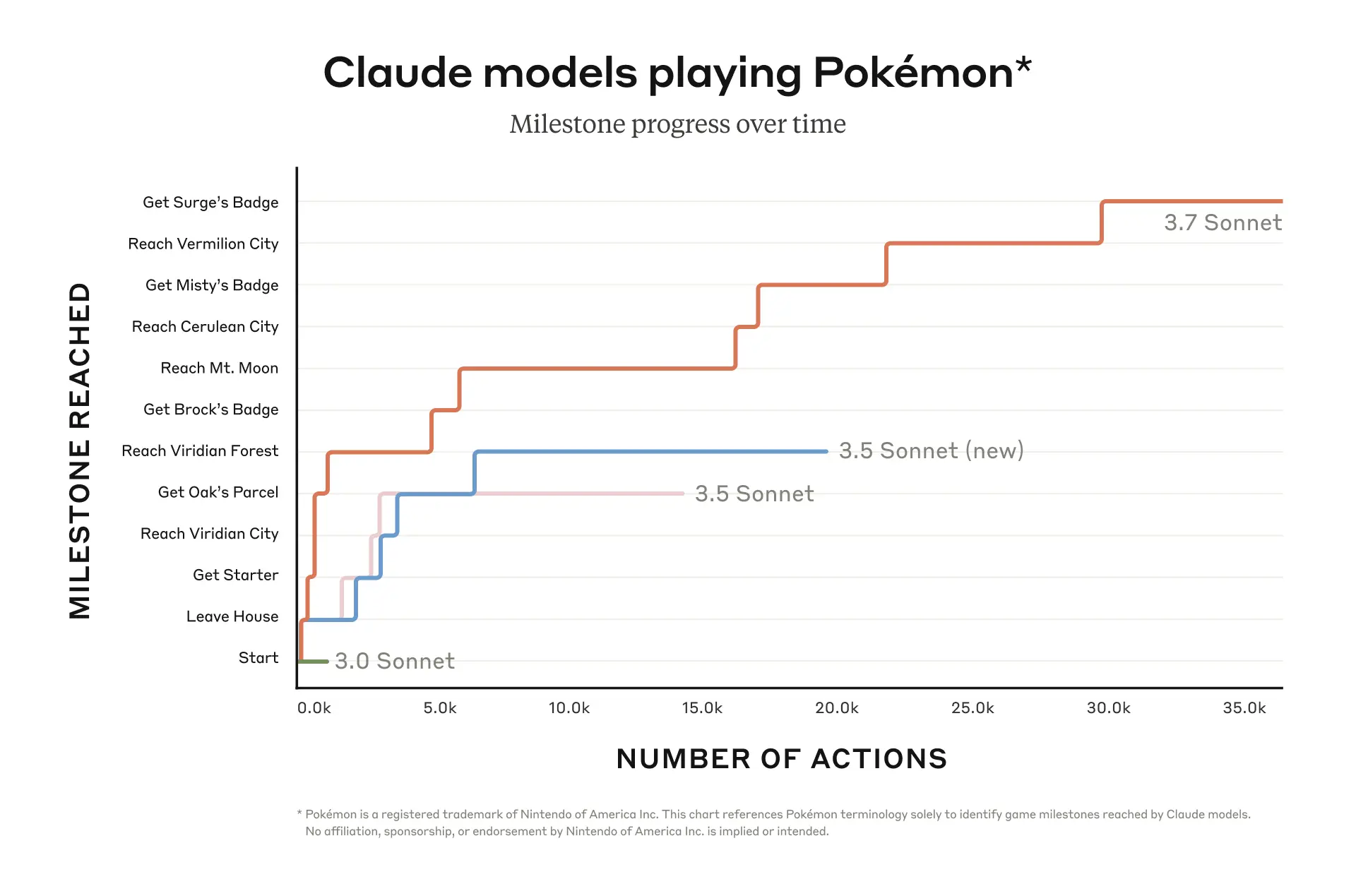
Concernant ses récents tests de gameplay, Anthropic a noté : « Pokémon est une façon amusante d'apprécier les capacités de Claude 3.7 Sonnet, mais nous nous attendons à ce que ces capacités aient un impact réel bien au-delà du simple fait de jouer à des jeux. »
L'une des particularités de Claude 3.7 Sonnet est sa capacité à « réfléchir de manière approfondie ». À l'instar de R1 de DeepSeek et d'o3-mini d'OpenAI, Claude 3.7 Sonnet est capable de résoudre des problèmes plus complexes. Pour ce faire, il nécessite plus de temps et, par conséquent, une puissance de calcul accrue.
On ignore encore la puissance de calcul consommée par Claude 3.7 pour atteindre les objectifs mentionnés. De même, Anthropic n'a pas précisé le temps nécessaire au modèle pour vaincre Surge, le dernier champion d'arène du jeu.
On peut supposer sans risque que les tests effectués avec Pokémon Rouge ne sont qu'une manière ludique de présenter les capacités du nouveau modèle. Ils démontrent simplement que ce dernier est capable d'un raisonnement plus poussé et pourrait prendre plus de temps (si nécessaire) pour résoudre des problèmes plus complexes. Après tout, les chercheurs testent souvent les capacités de leurs modèles en leur faisant jouer à des jeux vidéo comme Street Fighter, aux échecs, etc.
Claude 3.7 Sonnet peut réfléchir aussi longtemps que l'utilisateur le souhaite
Claude 3.7 Sonnet semble capable de réfléchir aussi longtemps que l'utilisateur le souhaite. Présenté comme un « modèle de raisonnement hybride basé sur l'IA », il fournit des réponses en temps réel ainsi que des réponses réfléchies. L'utilisateur peut activer ou non ses capacités de raisonnement, ce qui influence le temps de réflexion de Claude 3.7 Sonnet.
L'objectif semble être d'améliorer l'expérience utilisateur en simplifiant les options. La plupart des chatbots actuels proposent un sélecteur de modèle assez complexe pour l'utilisateur lambda. Ces modèles offrent généralement de nombreux paramètres et des fonctionnalités variées. Par exemple, ChatGPT d'OpenAI propose lui aussi un large éventail d'options.
En effet, Sam Altman a récemment indiqué dans la feuille de route mise à jour de son entreprise que l'objectif à long terme d'OpenAI est d'unifier les services de ChatGPT afin que les utilisateurs puissent trouver des solutions à leurs problèmes en mobilité. Dans cette optique, ChatGPT pourrait également adopter une approche centrée sur les agents.
Le Claude 3.7 Sonnet est plus cher que le DeepSeek R1 et l'o3-mini
Anthropic a récemment déployé Claude 3.7 Sonnet auprès des développeurs et des utilisateurs lundi. Cependant, les fonctionnalités de raisonnement du modèle ne sont accessibles qu'aux abonnés aux formules premium de chatbot. Pour l'instant, le coût est de 3 $ par million de jetons d'entrée et de 15 $ par million de jetons de sortie. Cela signifie qu'un utilisateur peut saisir 750 000 mots pour 3 $. Par conséquent, il est plus cher que R1 de DeepSeek et o3-mini de ChatGPT. Toutefois, contrairement à Claude 3.7 Sonnet, ces deux derniers ne sont pas des modèles hybrides ; ce sont des modèles de raisonnement à part entière
Les modèles de raisonnement sont généralement plus lents et mettent plus de temps à répondre à une question. Parmi les exemples, citons Grok 3 (Think) de xAi, Gemini 2.0 Flash Thinking de Google, R1 de DeepSeek et, bien sûr, le modèle o3-mini de ChatGPT.
Selon Dianne Penn, responsable produit et recherche chez Anthropic, l'entreprise souhaite que Claude puisse décider du temps de réflexion sur un problème, sans que les utilisateurs aient à choisir explicitement les paramètres. À ce sujet, Anthropic a déclaré dans un article de blog : « De la même manière que les humains n'ont pas deux cerveaux distincts pour les questions auxquelles on peut répondre immédiatement et celles qui nécessitent réflexion. »
Cependant, contrairement à Grok 3 de xAI, qui se veut moins restrictif et plus ouvert à la discussion, Claude 3.7 Sonnet refuse de répondre à certaines questions. En effet, au début du mois, la version bêta de Grok 3 est allée jusqu'à suggérer une pénalité ad*ath pour Trump, une erreur qualifiée de « terrible et grave » qui a depuis été corrigée, comme l'a confirmé Igor Babuschkin, directeur de l'ingénierie chez xAI.

Cependant, comparé à ses modèles précédents, il refuse moins souvent et est capable de distinguer les incitations bienveillantes des incitations nuisibles. Selon Anthropic, les refus injustifiés ont été réduits de 45 % par rapport au modèle précédent, Claude 3.5 Sonnet.
Si vous lisez ceci, vous avez déjà une longueur d'avance. Restez-y grâce à notre newsletter.
Avertissement : Les informations fournies ne constituent pas un conseil en investissement. CryptopolitanCryptopolitan.com toute responsabilité quant aux investissements réalisés sur la base des informations présentées sur cette page. Nous voustronrecommandons vivement d’effectuer vosdent et/ou de consulter un professionnel qualifié avant toute décision d’investissement.

Shummas Humayun
Shummas est une ancienne rédactrice de contenu technique et chercheuse.










- Quelles cryptomonnaies peuvent vous faire gagner de l'argent ?
- Comment renforcer la sécurité de votre portefeuille (et lesquels valent vraiment la peine d'être utilisés)
- Stratégies d'investissement peu connues utilisées par les professionnels
- Comment débuter en investissement crypto (quelles plateformes d'échange utiliser, quelles cryptomonnaies acheter, etc.)