



最优质的加密货币资讯直接发送到您的邮箱。.

- Anthropic 使用任天堂 Game Boy 上的 Pokémon Red 对其最新的 Claude 3.7 Sonnet 型号进行了基准测试。.
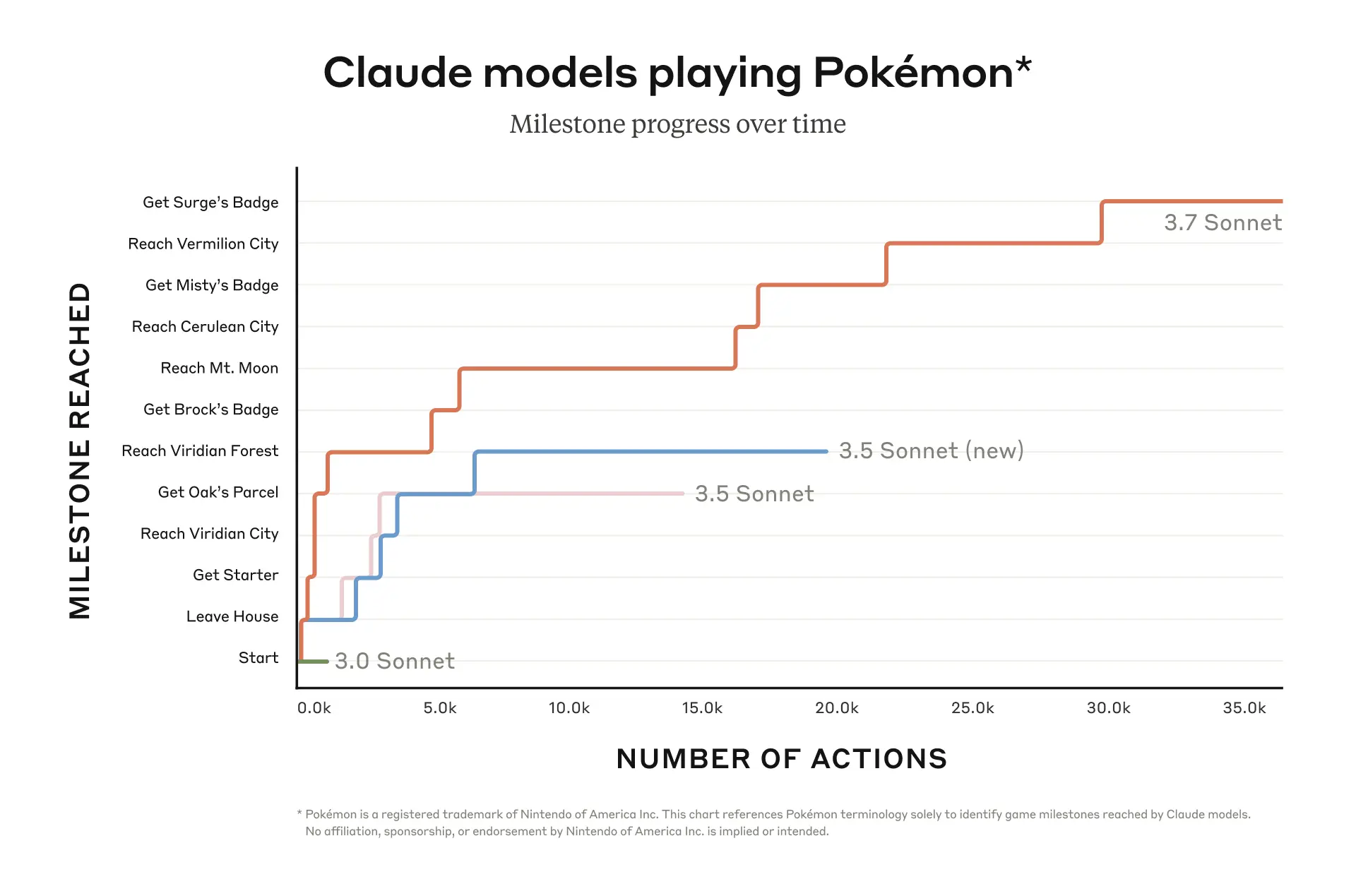
- 该模型在游戏中实现了 12 个里程碑,并执行了超过 35000 次操作。.
- Claude 3.7 Sonnet 可以根据问题的复杂程度,在用户希望的范围内“思考”。.
Anthropic公司使用任天堂Game Boy上的 classic 游戏《精灵宝可梦 红》对其最新的AI模型Claude 3.7 Sonnet进行了基准测试。与之前的版本相比,该模型表现显著提升,并成功完成了游戏中的12个里程碑。.
在最近的一篇 博文,Anthropic 公布了其近期测试的详情。该公司发布了一张图表,纵轴代表游戏中的“里程碑”,横轴代表“操作次数”。图表对比了 3.7 Sonnet 与 3.5 Sonnet(新款)、3.5 Sonnet 和 3.0 Sonnet 的性能。在这些型号中,3.7 的性能明显更胜一筹,它完成了超过 3.5 万次操作,达成了 12 个里程碑。它成功击败了游戏中的 3 位道馆馆主,并获得了相应的徽章。相比之下,Anthropic 的早期型号 3.0 Sonnet 只能完成几千次操作,甚至无法通过游戏的初始关卡。
关于最近的游戏测试,Anthropic 指出:“宝可梦是体验 Claude 3.7 Sonnet 功能的有趣方式,但我们期望这些功能在现实世界中的影响远远超出玩游戏的范畴。”
Claude 3.7 Sonnet 的一个独特之处在于它能够进行“扩展思考”。与 DeepSeek 的 R1 和 OpenAI 的 o3-mini 一样,Claude 3.7 Sonnet 能够推理解决更具挑战性的问题。它通过花费更多时间,并相应地使用更强大的计算能力来实现这一点。.
目前尚不清楚Claude 3.7为达到上述里程碑消耗了多少计算能力。此外,Anthropic Games也未说明该模型花了多长时间才到达游戏中最后一个道馆馆主——马志士的所在地。.
可以肯定的是,《精灵宝可梦 红》的测试只不过是一种轻松的方式来展示新模型的性能。它表明新模型具备扩展推理能力,并且(如有必要)可以花费更多时间来解决更复杂的问题。毕竟,研究人员经常通过让模型玩《 街头霸王》、国际象棋等电子游戏来测试它们的性能。
Claude 3.7 Sonnet 可以思考用户想要思考的时长。
显然,Claude 3.7 Sonnet 能够根据用户的意愿进行思考。它被誉为“混合型人工智能推理模型”,因为它既能提供实时答案,也能提供深思熟虑的回应。是否开启其推理功能完全取决于用户,开启后 Claude 3.7 Sonnet 解决问题所需的时间长短也会有所不同。.
看来此举旨在通过简化选项来提升用户体验。目前大多数聊天机器人的模型选择器对普通用户来说都相当复杂。这些模型通常提供一系列设置,功能也各不相同。例如,OpenAI 的 ChatGPT 也提供了丰富的功能。.
事实上,Sam Altman 最近在其公司 更新的路线图 ,OpenAI 的长期目标是统一 ChatGPT 的各项功能,以便用户随时随地搜索问题的解决方案。从这个意义上讲,ChatGPT 也可能采用以代理为中心的方法。
Claude 3.7 Sonnet 比 DeepSeek R1 和 o3-mini 更贵。
Anthropic 于周一正式向开发者和用户推出了 Claude 3.7 Sonnet。然而,该模型的推理功能仅对选择高级聊天机器人套餐的用户开放。目前,其价格为每百万输入词条 3 美元,每百万输出词条 15 美元。这意味着用户只需 3 美元即可输入 75 万个单词。因此,它的价格高于 DeepSeek 的 R1 和 ChatGPT 的 o3-mini。但是,这两个模型并非像 Claude 3.7 Sonnet 那样的混合模型,而是纯粹的“推理模型”。
推理模型通常运行速度较慢,需要更多时间才能回答问题。例如,xAi 的 Grok 3(Think)、谷歌的 Gemini 2.0 Flash Thinking、DeepSeek 的 R1,当然还有 ChatGPT 的 o3-mini 模型。.
据 Anthropic 的产品和研究主管 Dianne Penn 称,该公司希望 Claude 能够自行决定思考问题的时间,而不是让用户明确地选择设置。对此,Anthropic 在其 博客文章:“这就像人类的大脑并非分别处理可以立即回答的问题和需要思考的问题一样。”
然而,与xAI的Grok 3(力求减少限制、更开放地进行讨论)不同,Claude 3.7 Sonnet会拒绝回答某些问题。事实上,就在本月初,Grok 3的测试版甚至建议对特朗普使用ad*ath惩罚,这被认为是一个“糟糕透顶的错误”,但xAI的工程主管Igor Babuschkin已证实,该错误已被修正。.

然而,与之前的模型相比,它的拒绝频率更低,并且能够区分良性提示和有害提示。据 Anthropic 公司称,与之前的模型 Claude 3.5 Sonnet 相比,不必要的拒绝减少了 45%。.
如果你正在阅读这篇文章,你已经领先一步了。 订阅我们的新闻简报,继续保持领先优势。
免责声明:本页面提供的信息并非交易建议。Cryptopolitan.com对任何基于本页面信息进行的投资概不负责。我们tron您在做出任何投资决定前进行独立dent /或咨询合格的专业人士。Cryptopolitan研究

舒马斯·胡马云
Shummas 曾是一名技术内容撰稿人和研究员。










学速成课程
- 哪些加密货币可以让你赚钱
- 如何通过钱包提升安全性(以及哪些钱包真正值得使用)
- 专业人士使用的鲜为人知的投资策略
- 如何开始投资加密货币(使用哪些交易所、购买哪种加密货币最划算等)