



Best crypto insights delivered straight to your inbox.
Anthropic benchmarked its latest Claude 3.7 Sonnet AI model using Pokémon Red

- Anthropic benchmarked its newest Claude 3.7 Sonnet model using Pokémon Red on Nintendo’s Game Boy.
- The model was able to achieve 12 milestones in-game and performed over 35k actions.
- Claude 3.7 Sonnet can “think” as long as the user wants it to depending on the complexity of the problem.
Anthropic benchmarked its latest AI model, Claude 3.7 Sonnet, on the classic game Pokémon Red on Nintendo’s Game Boy. The model performed significantly better as compared to the previous versions and managed to complete 12 milestones in the game.
In a recent blog post, Anthropic revealed details of its recent tests. The company published a graph, showing the in-game ‘Milestones’ on the Y-axis and ‘Number of actions’ on the X-axis. It compared the performance of the 3.7 Sonnet with the 3.5 Sonnet (new), 3.5 Sonnet, and 3.0 Sonnet. Among these models, 3.7 visibly performed better, as it performed over 35k actions to achieve a total of 12 milestones. It was successful against 3 gym leaders in the game and won the respective badges. For comparison, Anthropic’s earlier model, 3.0 Sonnet, could only take a few thousand actions and couldn’t cross the game’s starting stages.
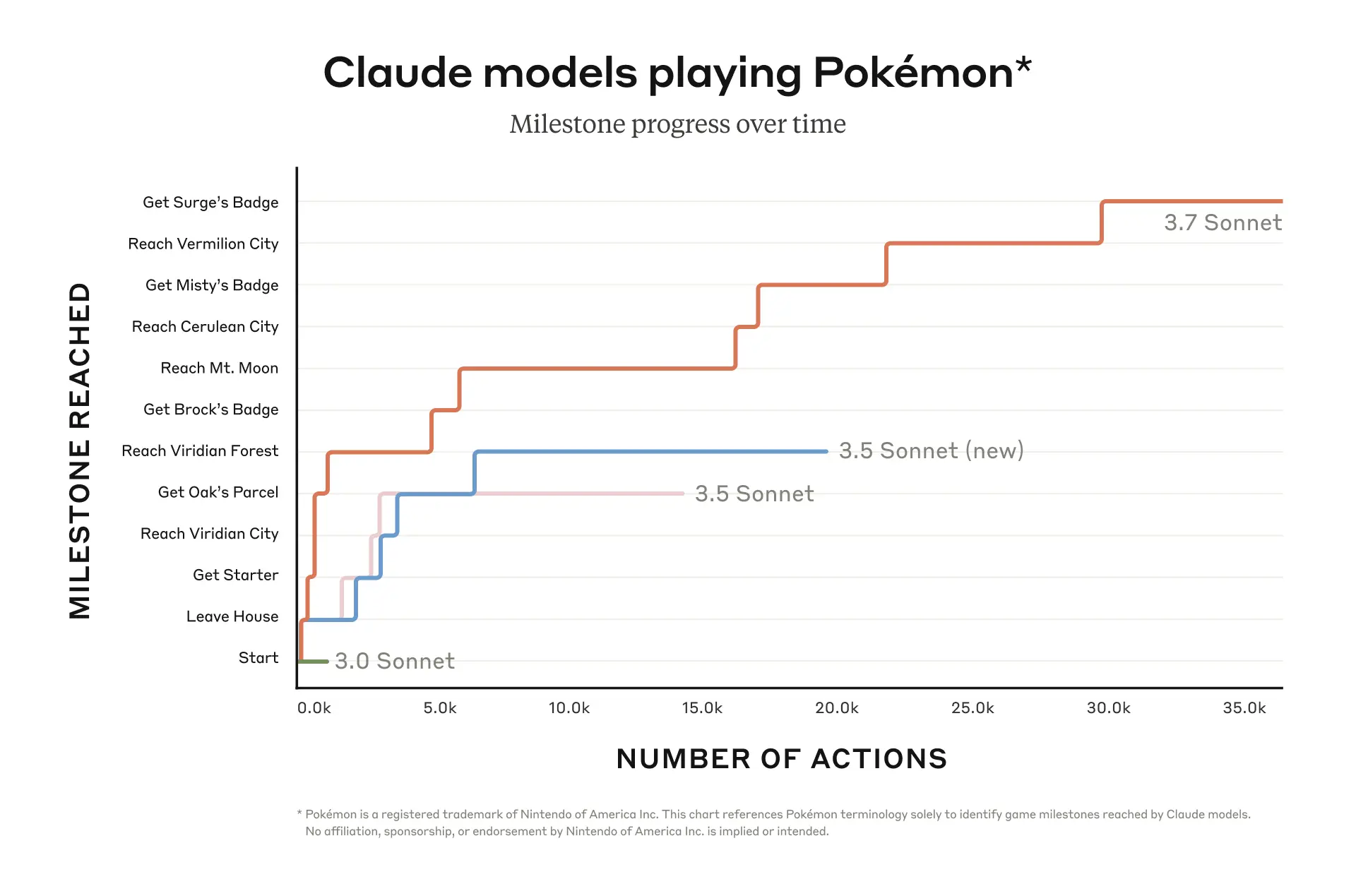
Regarding its recent gameplay tests, Anthropic noted, “Pokémon is a fun way to appreciate Claude 3.7 Sonnet’s capabilities, but we expect these capabilities to have a real-world impact far beyond playing games.”
One unique feature of Claude 3.7 Sonnet is that it engages in “Extended thinking.” Just like DeepSeek’s R1 and o3-mini by OpenAI, Claude 3.7 Sonnet is capable of reasoning through problems that are more challenging. It does this by taking more time, and in return, using more computing power.
It is not yet clear how much computing power Claude 3.7 consumed to achieve the aforementioned milestones. Also, Anthropic hasn’t made it clear how much time the model took to reach Surge, the last gym leader in the game.
It’s safe to assume that Pokémon Red’s testing is nothing more than a light-hearted way of displaying the new model’s capabilities. It just shows that the new model is capable of extended reasoning and could take more time (if required) to solve more complex problems. After all, researchers have frequently started testing the capabilities of their models by getting them to play video games such as Street Fighter, chess, and more.
Claude 3.7 Sonnet can think as long as the user wants
Apparently, Claude 3.7 Sonnet is capable of thinking as long as the user wants. It’s touted as a “hybrid AI reasoning model” because it gives real-time answers along with thought-out responses. It is up to the user whether to turn on its reasoning abilities, which results in Claude 3.7 Sonnet spending more or less time on the problem.
It seems like the goal here is to improve the user experience by simplifying the options. Most chatbots today have a model picker that is rather confusing for the average user. These models usually have a range of settings and vary in capabilities. For instance, OpenAI’s ChatGPT has a wide range of offerings too.
In fact, Sam Altman recently mentioned in his company’s updated roadmap that the long-term goal of OpenAI is to unify ChatGPT’s offerings so that users can search solutions to their problems on-the-go. In that sense, ChatGPT may also take an agent-centric approach.
Claude 3.7 Sonnet is more expensive than DeepSeek R1 and o3-mini
Anthropic recently rolled out Claude 3.7 Sonnet to developers and users on Monday. However, the model’s reasoning features are only available to those who pick the premium chatbot plans. As of yet, it costs only $3 per million input tokens and $15 per million output tokens. This means that a user can enter 750,000 words for $3. Hence, it is more expensive than both R1 by DeepSeek and o3-mini by ChatGPT. However, these two models are not hybrids like Claude 3.7 Sonnet, they are very strictly ‘reasoning models.’
Reasoning models generally work slower and take more time to answer a question. Some examples include xAi’s Grok 3 (Think), Google’s Gemini 2.0 Flash Thinking, R1 by DeepSeek, and of course, ChatGPT’s o3-mini model.
According to Dianne Penn, product and research lead at Anthropic, the company wants Claude to be able to decide how long it will think about a problem instead of users having to explicitly choose the settings. Regarding this, Anthropic stated in its blog post, “Similar to how humans don’t have two separate brains for questions that can be answered immediately versus those that require thought.”
However, unlike xAI’s Grok 3, which tries to be less restrictive and more open to discussions, Claude 3.7 Sonnet will refuse to answer certain questions. In fact, earlier this month, Grok 3’s beta version went as far as suggesting a d*ath penalty for Trump, a supposedly “terrible and bad failure” which has since been corrected, as confirmed by xAI’s head of engineering, Igor Babuschkin.

However, as compared to its previous models, it refuses less often and is capable of making distinctions between benign prompts and harmful prompts. According to Anthropic, the unnecessary refusals have been reduced by 45% when compared with the previous model, Claude 3.5 Sonnet.
If you're reading this, you’re already ahead. Stay there with our newsletter.
Disclaimer. The information provided is not trading advice. Cryptopolitan.com holds no liability for any investments made based on the information provided on this page. We strongly recommend independent research and/or consultation with a qualified professional before making any investment decisions.

Shummas Humayun
Shummas is a former technical content writer and a researcher.










CRASH COURSE
- Which cryptocurrencies can make you money
- How to boost your security with a wallet (and which ones are actually worth using)
- Little-known investment strategies that the pros use
- How to get started investing in crypto (which exchanges to use, the best crypto to buy etc)